Update(2024/10/11)
We are excited to share the source code and an interactive demo for this research. The GitHub repository contains all the necessary scripts and instructions to reproduce our experiments. Additionally, you can experience our result through the huggingface demo. We encourage researchers and practitioners to utilize these resources, provide feedback, and contribute to further advancements in this field.
Abstract
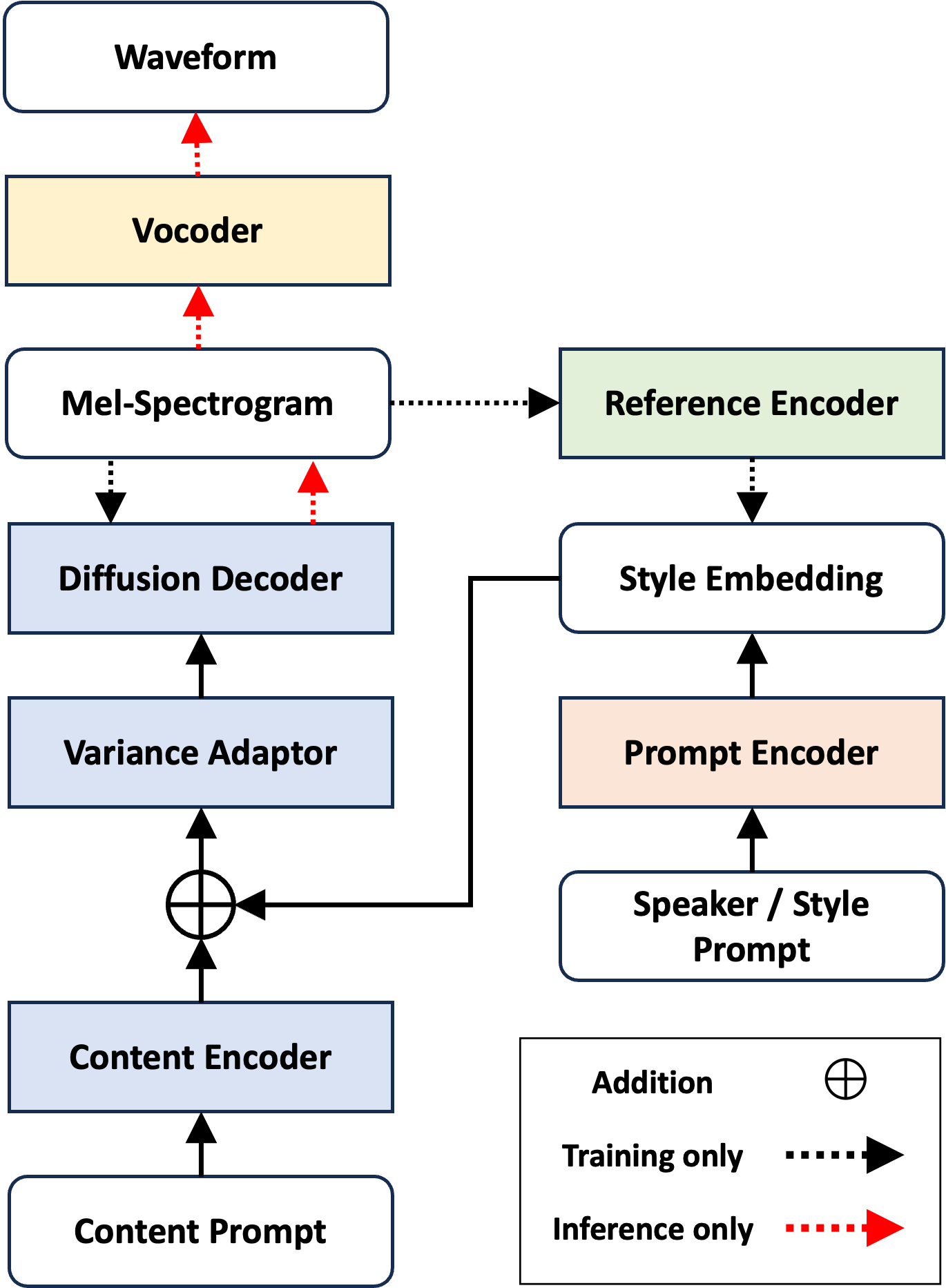
We propose PromptTTS++, a prompt-based text-to-speech synthesis (TTS) system that allows control over speaker identity using natural language descriptions. To control speaker identity within the prompt-based TTS framework, we introduce a concept of speaker prompt, which is a description of voice characteristics (e.g., gender-neutral, young, old, and muffled) designed to be approximately independent to speaking style. Since there was no large-scale dataset containing speaker prompts, we first construct a dataset based on the LibriTTS-R corpus with manually annotated speaker prompts. We then employ a diffusion-based acoustic model with mixture density networks to model diverse speaker factors in the training data. Unlike previous studies that rely on style prompts describing only a limited aspect of speaker individuality such as pitch, speaking speed and energy, our method utilizes an additional speaker prompt to effectively learn the mapping from natural language descriptions to the acoustic features of diverse speakers. Subjective evaluation results demonstrate that our method can control speaker characteristics based on the given text prompt.
Audio samples
There are some audio samples from train/eval dataset generated by proposed and other comparison methods. The groundtruth audio clips are from the LibriTTS-R dataset[1].
Training data
The table below shows the audio samples generated from the training data, using their corresponding speaker / style prompts.
1. The speaker identity can be described as low-pitched, calm, slightly middle-aged, slightly dark, adult-like, mature, cool, slightly intellectual, deep, masculine.
| Model | Text: "This must be a day of festival and worship, devoted to one of their gods," I murmured to myself. |
|---|---|
| Ground truth | |
| Baseline | |
| w/o MDN, speaker prompt | |
| w/o speaker prompt | |
| w/o MDN | |
| Proposed | |
| Proposed w/ reference speech |
2. The speaker identity can be described as slightly refreshing, weak, slightly clear, slightly relaxed, very young, very feminine, fluent, very cute.
| Model | Text: I thank you for the kindness you have shown me, which has made me your friend for ever. |
|---|---|
| Ground truth | |
| Baseline | |
| w/o MDN, speaker prompt | |
| w/o speaker prompt | |
| w/o MDN | |
| Proposed | |
| Proposed w/ reference speech |
Evaluation data
The table below shows the audio samples generated from the evaluation data, using their corresponding speaker / style prompts.
1. The speaker identity can be described as low-pitched, wild, middle-aged, strong, mature, cool, deep, fluent, masculine, powerful, lively.
| Model | Text: The machinery was taken up in pieces on the backs of mules from the foot of the mountain. |
|---|---|
| Ground truth | |
| Baseline | |
| w/o MDN, speaker prompt | |
| w/o speaker prompt | |
| w/o MDN | |
| Proposed | |
| Proposed w/ reference speech |
2. The speaker identity can be described as feminine, refreshing, adult-like, slightly strong, slightly cool, slightly intellectual, soft, young, slightly muffled, lively.
| Model | Text: "I can't pray to have the things I want," he said slowly,
"and I won't pray not to have them, not if I'm damned for it." |
|---|---|
| Ground truth | |
| Baseline | |
| w/o MDN, speaker prompt | |
| w/o speaker prompt | |
| w/o MDN | |
| Proposed | |
| Proposed w/ reference speech |
Ex: Pitch control
The table below presents audio samples generated by the proposed model with varying pitch levels (low/normal/high).
Male samples
| Low | Normal | High |
|---|---|---|
Female samples
| Low | Normal | High |
|---|---|---|
Ex: Sampling
The table below demonstrates the capability of the proposed model to generate a diverse range of
speakers.
Samples in the same row are generated from the same content and style prompt.
Male samples
| sample1 | sample2 | sample3 |
|---|---|---|
Female samples
| sample1 | sample2 | sample3 |
|---|---|---|